Following slide deck presents Siddhi, a University of Moaratuwa final year project I worked with Suho, Isuru, Subash, and Kasun last year. Siddhi is a Complex Event Processing Implementation that incorporates most of the state of the art advances.
Siddhi: A Second Look at Complex Event Processing Implementations
We presented the Siddhi paper titled Siddhi: A Second Look at Complex Event Processing Architectures, in Gateway Computing Environments Workshop (GCE), Seattle, 2011 (Co-located with Super Computing 2011). Above slides provide an outline of our work.
Following three graph's shows some of the key results of the Paper. Other CEP engine is Esper, which is a well-known opensource CEP engine. In the given scenarios we did from about 0.3 times to 10 times better.
Query 1: Filter (select symbol, price from StockTick(price>6))

Query2: Window (select irstream symbol, price, avg(price) from StockTick(symbol=’IBM’).win:time(.005))

Query3: Followed by pattern (select f.symbol, p.accountNumber, f.accountNumber from pattern [every f=FraudWarningEvent2 -> p=PINChangeEvent2(accountNumber= f.accountNumber)])

Siddhi is currently being used by
Siddhi: A Second Look at Complex Event Processing Implementations
Following three graph's shows some of the key results of the Paper. Other CEP engine is Esper, which is a well-known opensource CEP engine. In the given scenarios we did from about 0.3 times to 10 times better.
Query 1: Filter (select symbol, price from StockTick(price>6))
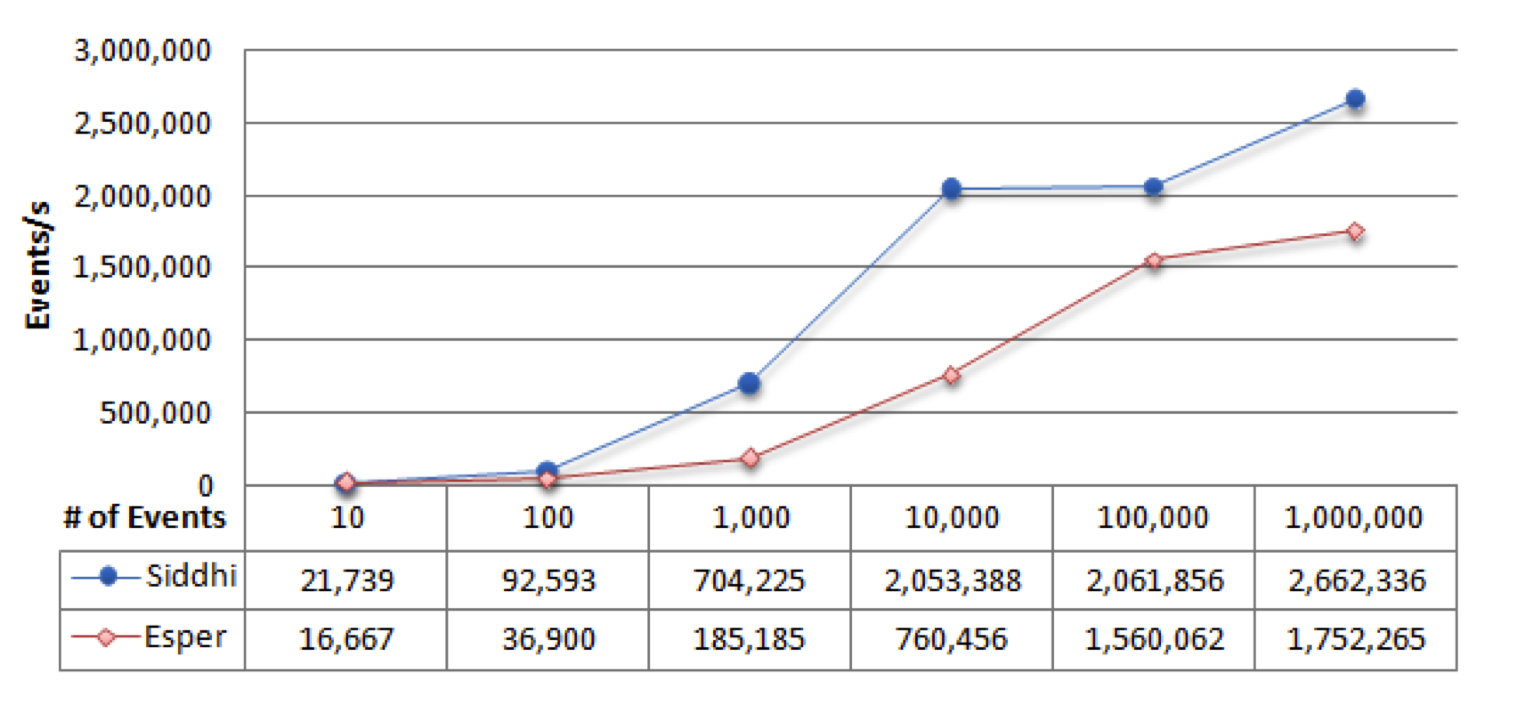
Query2: Window (select irstream symbol, price, avg(price) from StockTick(symbol=’IBM’).win:time(.005))

Query3: Followed by pattern (select f.symbol, p.accountNumber, f.accountNumber from pattern [every f=FraudWarningEvent2 -> p=PINChangeEvent2(accountNumber= f.accountNumber)])

Siddhi is currently being used by
- Los Angeles Smart Grid Demonstration Project
- It forecasts electricity demand, respond to peak load events, and improves sustainable use of energy by consumers.
- Open MRS NCD module – idea is to detect and notify patient when certain conditions have occurredhttps://wiki.openmrs.org/display/docs/Notifiable+Condition+Detector+%28NCD%29+Module


