An updated version of the post is found at A Gentle Introduction to Stream Processing.
What and Why of Realtime Analytics?
I am sure you have heard enough about Big Data, the idea of “processing data and extracting actionable insights from data”. Most Big Data applications use batch processing technologies like Hadoop or Spark, which will need us to store data in a disk and later process them.
Batch processing often takes few minutes to generate an output, and with large datasets, it can take hours. However, there are lot of use cases where it is much useful to know results faster.
For example, think about traffic data collected from counting vehicles at each traffic light. We can use Hadoop or Spark to analyze this data. Among useful insights can be “traffic hotspots”, “traffic trends over time” etc. It is interesting to know after a one hour, there was traffic in “US-101”. On the other hand, It is much more useful to know there is traffic now, so one could avoid it.
There are lot and lot of use cases like this where outcome is important and there is a chance that we can act to fix if there is a problem. Following are few of them.
- Algorithmic Trading
- Smart Patient Care
- Monitoring a production line
- Supply chain optimisations
- Intrusion, Surveillance and Fraud Detection
- Most Smart Device Applications : Smart Car, Home ..
- Smart Grid
- Vehicle and Wildlife tracking
- Sport analytics
- Context aware promotions and advertising
Realtime analytics let you analyze data as they come in and make important decisions within milliseconds to few seconds.
How to do Realtime Analytics?
OK, great how can we do real time analytics?
Lets start with an example. Let us say you want to know how many visitors and in your site and be notified if there are more than 10000 visitors came in within last 30 minutes. However, you want to know that the condition has met right away.
Whenever visitor do something in your site, it sends events that looks like following. Ignore the syntax for now, but read what it means.
define stream SiteVistors(ts long, email string, url string)
Try 1: People first tried to do this by optimizing Hadoop having lot of processing nodes. With lot of machine and tuning you can bring down Hadoop job execution time to few seconds. This, however, is like trying to do your water supply using buckets instead of pipes. Chances are that it will break when 1) you change your query a bit, 2) when data has grown, or 3) when two batch jobs run at the same time. Also not to mention you will be using about 10X hardware than you will need.
For example, to do our use case, we would need to run Hadoop on last 30 minutes of data to count the number of visits, and likely we will have to run it back to back starting another run once a run has completed.
Try 2: Google had the same problem, and they solved it with Dremel (which later made available as “Big Query”). Dremel let you issue queries over a large set of data and get responses within few seconds by breaking up and processing data using several machines in parallel. If you want this technology, Apache Drill is an opensource implementation of the idea.
Try 3: You can do this faster via In-Memory computing. Idea is to have lot of memory, load pr keep all the data to memory (do compressions and cool algorithms like Sketching when possible), and process the data. Since data is in memory, it will be much faster. For more information, please checkout a white paper and the slide deck I have done about the topic.
However, all above three are ways to make batch processing faster. Batch processing would just collect data for a period of time, and only try to process data when all the data has been received. Basically, we sit idle for first 30 minutes just collecting data and try to do it as fast as possible when 30 minutes has passed.
From that perspective, it is a bad idea to use batch processing to do this. There is much better way to do this. Idea is to process data as they come in, and that way once we have all the data, we can produce the results right away.
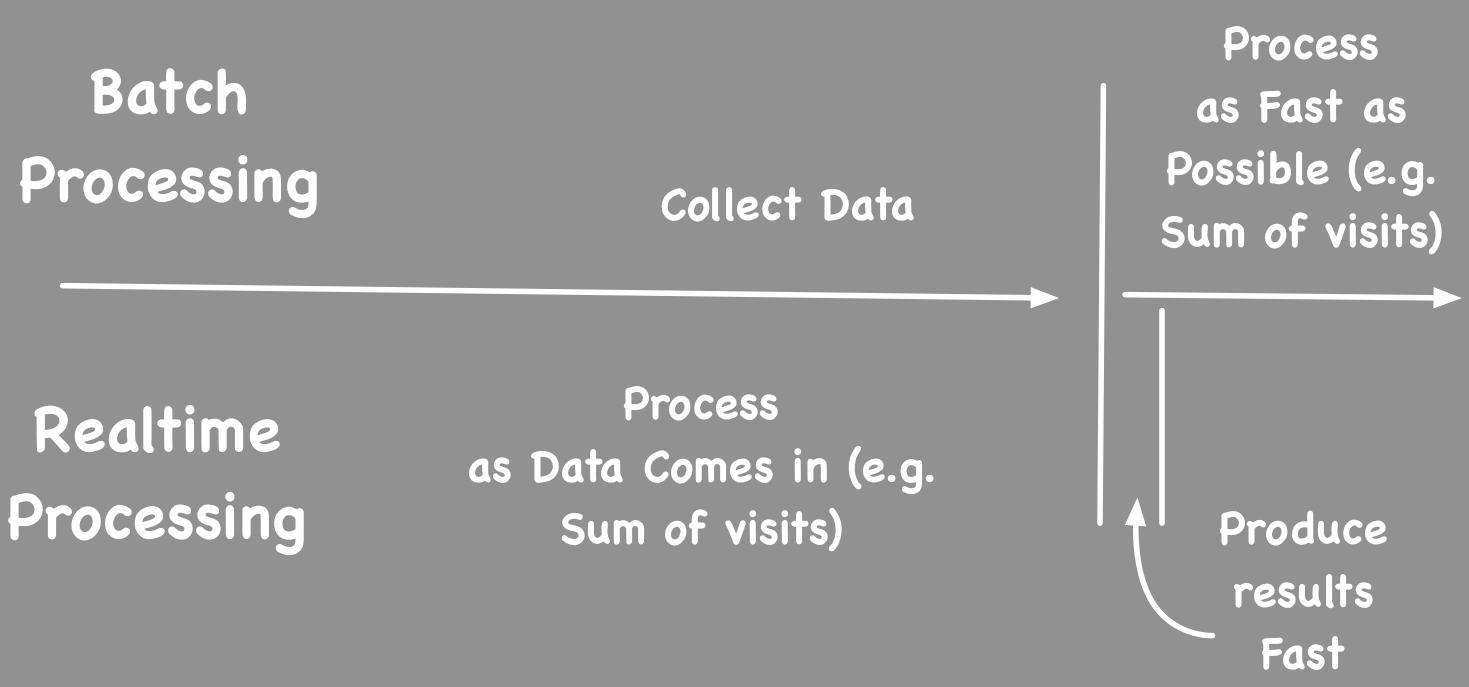
Such technology (called Stream Processing) has been around for more than 10 years and used in use cases like Stock trading. Main idea is to create a graph of processing nodes (each can be stateful) and data get processed as they flow through the graph. (e.g. IBM InfoStreams, Tibco Stream Base).
Fast forward to now, we have two classes of technologies to do this now: Stream Processing (e.g. Apache Storm) and Complex Event Processing (e.g. WSO2 CEP, Esper).
Think of Apache Storm as Hadoop for Streaming data. Idea is you write code for processing nodes called Bolts and wire them up to a graph called topology. Storm will keep this topology running. In our example, several processing nodes will track sum of visits for a given window of time and one master node can receive sums from other nodes and check sum of those sums for a condition ( for more info about code, see Word Count with Storm).
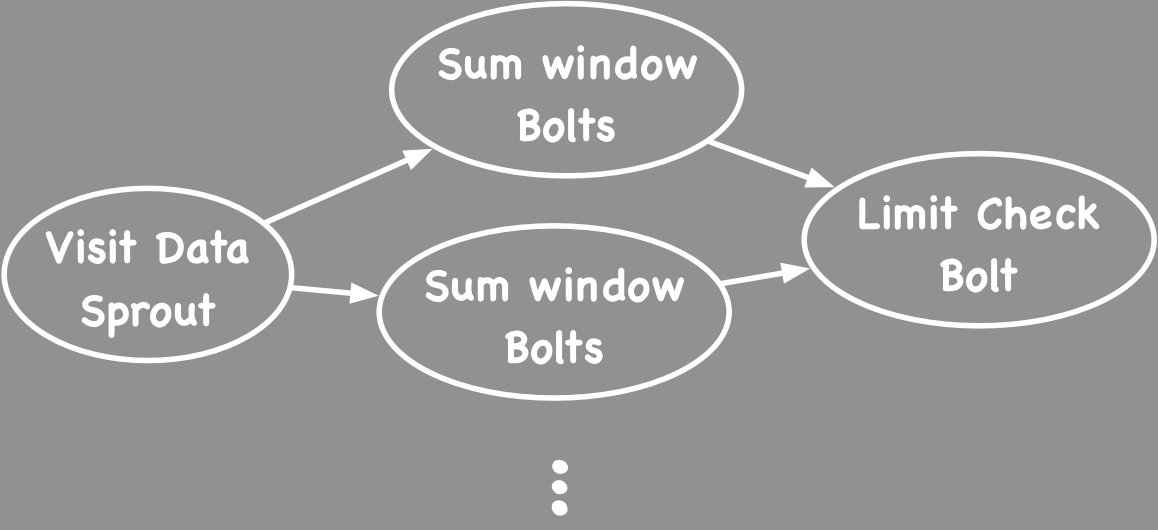
Great, then why Complex Event Processing? It is best explained through an analogy. You may have heard about Hive, which is a SQL on top of Hadoop (MapReduce). With Hadoop, you can write java code and get something done, but with Hive you can write an SQL query to get the most of the same things done. Latter is simpler and lot of people understand SQL.
Think of Complex Event Processing (CEP) as SQL on top of Storm. (Well technically there are deep differences, if you want to get to it, see 1 and 2). However, with over the time both technologies has shared more and more features. If you are a programmer, CEP would look like SQL on top of Storm. For example, see SQLStream samples http://www.sqlstream.com/examples/ and also WSO2 CEP 4.0 version, which will run your CEP query on top of Storm.)
For example our example on top of CEP will be look like following.
from SiteVistors#window.timeBatch[30m]
select email, sum(url) as sum
having sum > 10000
Here #window.timeBatch[30m] says collect data in 30 minute window and process the query. If you want processing to be done in parallel with many machines, the query will look like following.
//define the partition
define partition SiteVistorsParition SiteVistors.email;
//process data within partition
from ParitionedSiteVistors#window.timeBatch[30m]
select email, sum(url) as sum
insert into SiteVistorsSums;
using partition SiteVistorsParition;
//sum up the sums and check
from SiteVistorsSums#window.timeBatch[1s]
select sum(sum) as fsum
having fsum > 10000
Just like Hive, CEP technologies has lot of operators that you can directly use like Filters, Joins, Windows, and Event Patterns. See my earlier post for more details.
Conclusion
So we discussed what is Realtime analytics, Why we need it, and How to do it. Real Time analytics has lot of use cases that are very hard to implement with MapReduce style batch processing, and trying to make such use cases faster using MapReduce often eat up resources.
Having said that technologies like Apache Drill and Isolutions like SAP Hana have their own use case, which is interactive ad-hoc analytics. For Stream processing to work, you must know queries a priori. If you want to do ad-hoc queries, you need to use technologies like Apache Drill. So there are three types of use cases and you need use different solutions for each.
- Batch Processing - MapReduce, Sprak
- Real time analytics when queries are known a priori - Stream Processing
- Interactive Ad-hoc queries - Apache Drill, Hazecast, SAP Hana
Following Picture Summaries different tools and requirements.
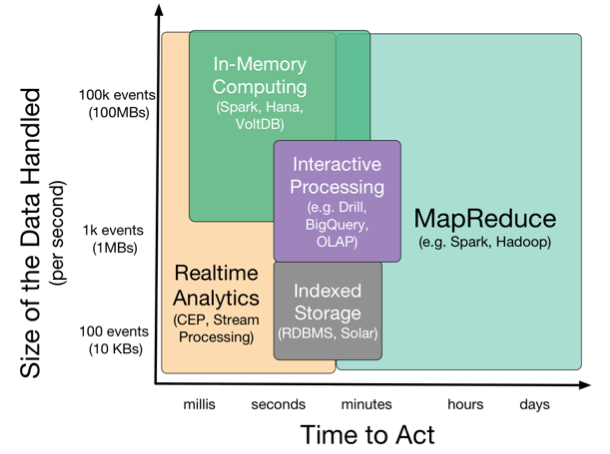
Y axis is amount of data (in size or as number of events), and X axis is time taken to produce the results. It outlines when each technology is useful.
Update 2017 September: You can try out above sample queries and ideas with WSO2 Stream Processor, which is freely available under Apache Licence 2.
Hope this was useful. If you enjoyed this post you might also like Stream Processing 101: From SQL to Streaming SQL and Patterns for Streaming Realtime Analytics.
No comments:
Post a Comment